1. Null-terminated strings
A null-terminated string is a sequence of bytes in memory where each byte encodes a single character using ASCII. The last character is followed by a byte containing all zero bits. That byte is called a null byte. For example, the string "The game is afoot!" is stored as:

In this picture, each yellow square represents a byte. The slash in the last cell represents the null byte. The empty cells represent the space character, represented in ASCII as the pattern 0x20.
2. ASCII
Historically, C programs have encoded characters as bit patterns using the ASCII encoding scheme. Although various libraries use other encoding schemes, ASCII remains the most popular and is used in these puzzles.
The following table shows the ASCII encoding scheme.
Each character is encoded as an 8-bit pattern. The table shows the pattern
using the hexadecimal name for the pattern. The column heading gives the 1's
place digit of the hex and the row heading gives the 16's place digit of the
hex. For example, find the character 'K' in the central (yellow) portion of
the chart. The row heading is 4 and the column heading is B so the bit pattern
is 0x4B, or
|
1's place |
||||||||||||||||
|
16's place |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
|
0 |
NUL |
SOH |
STX |
ETX |
EOT |
ENQ |
ACK |
BEL |
BS |
HT |
LF |
VT |
FF |
CR |
SO |
SI |
|
1 |
DLE |
DC1 |
DC2 |
DC3 |
DC4 |
NAK |
SYN |
ETB |
CAN |
EM |
SUB |
ESC |
FS |
GS |
RS |
US |
|
2 |
SP |
! |
" |
# |
$ |
% |
& |
' |
( |
) |
* |
+ |
, |
- |
. |
/ |
|
3 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
< |
= |
> |
? |
|
4 |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
|
5 |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\ |
] |
^ |
_ |
|
6 |
` |
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
|
7 |
p |
q |
r |
s |
t |
u |
v |
w |
x |
y |
z |
{ |
| |
} |
~ |
DEL |
Some characters in the chart are control characters, which
in the past were used to send commands to electro-mechanical equipment like teletypes
and printers. Control characters do not correspond to printed characters and
are shown in the chart as abbreviations. For example, BEL (0x07)
commands a device to sound its bell. Modern equipment will sometimes
sound a beep when it is sent BEL.
The control character line feed is 0x0A (abbreviated as LF).
This command told a device to move the paper it was printing on up by one line
so that the next line could be printed.
Carriage return, 0x0A (abbreviated as CR),
told a device to mechanically adjust itself so that the next
character would be printed at the beginning of a line.
With most electric typewriters, this meant to return the paper carriage to its starting position.
Typically, to start a new line, both CR and LF were sent to a device so that it
would advance the paper to a new line (LF) and then start at the beginning of that line (CR).
With modern software, when text is contained in main memory, LF marks the end of a line. (This is true for nearly all software, Unix, Linix, Microsoft, or Apple.) For text stored in a disk file, end of lines are marked by LF (in Unix systems), CR-LF (in Microsoft systems), or CR (older Apple systems).
Character SP (0x20) is the space character.
Character HT (0x09) is the horizontal tab. NUL
is the pattern 0x00—the null byte placed at the end of strings.
3. Characters as Integers
Often it is convenient to think of the bit pattern that represents a character as
encoding a small integer. For example, the bit pattern that represents 'A' is
0x41 (the bit pattern 01000001).
Think of this as an integer represented in base two.
If you add one to this integer you get 01000010,
which is the ASCII encoding for 'B'. The following code fragment sends the
sequence 'A', 'B', 'C', 'D' to standard output:
int ch = 'A' ; putchar( ch ); putchar( ch+1 ); putchar( ch+2 ); putchar( ch+3 );
The first statement puts the code for character 'A' into the low
order byte of the int variable ch.
Gotcha:
The literal 'A' stands for an int value
with the 8-bit ASCII code for the character in the low-order byte.
Characters are usually manipulated using int variables,
not char variables!
The function putchar()
requires an int argument,
but only sends the low order byte of that argument to standard output.
Often you want to convert a digit character into the corresponding integer. For example, you might want to convert the character '1' into the integer value one. The following does not work:
int value; value = '1';
The above places the ASCII encoding for character '1' into the low order byte of the variable. The variable gets:
0000 0000 0000 0000 0000 0000 0011 0001
(assuming that value is 32 bits).
What you really want in value is a 32-bit binary representation of one:
0000 0000 0000 0000 0000 0000 0000 0001
To get this into the variable, do this:
int value; value = '1' - '0';
Since the ASCII encoding for '1' immediately follows the encoding for '0', the subtraction evaluates to integer one.
4. Strings and Pointers
Strings are accessed through pointers. The printf()
function from the standard I/O library prints a a string to the monitor. For
example,
printf("The game is afoot!")
prints its string to the monitor. At run time, the string literal "The
game is afoot!" is a null terminated string placed somewhere in
memory. The actual argument sent to printf() is a pointer to the
first byte of that string:

The effect is the same as the following:
char *p; p = "The game is afoot!"; printf( p );
In the above code, the variable p contains a pointer to a char.
The function printf follows the pointer to the null-terminated
string in memory to find what it should print.
Consider this experiment: Add one to the pointer so that it points to the second character of the string. The following code:
char *p; p = "The game is afoot!"; p++ ; printf( p );
prints out "he game is afoot!" .
5. String Literals
A string literal is a sequence of characters contained between quote marks, like "The game is afoot!" The compiler allocates memory for it, puts the characters followed by a null byte into the memory, and provides the address of the first byte (a pointer to the first byte).
Bug Alert! In standard C, string literals are constants. They cannot be altered. The following is illegal:
char *p = "The game is afoot!"; *p = 'X' ;
The fragment is attempting to put 'X' into the first byte of the string literal, but changing a string literal is illegal. The compiler might not catch the error, so you will have a mysterious run-time error instead.
Unfortunately, many compilers do not enforce this, and with them the above code will compile and run. Worse, many C programs have been written using such compilers and when ported to a new compiler will no longer work.
6. String Buffers
Often programs allocate a generous amount of memory for a character array, more bytes than any string is expected to use. The strings that the program manipulates are stored in the array (and always terminated with a null byte). The array is used as a staging area, and is called a string buffer. For example the following buffer contains 1024 bytes, which is plenty of room for the strings it is dealing with:
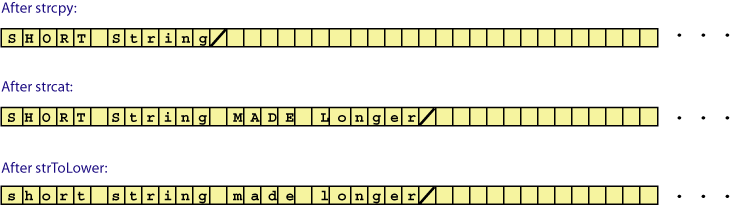
char buffer[1024]; strcpy( buffer, "SHORT String" ); strcat( buffer, " MADE Longer"); strToLower( buffer );
The first function copies characters into the buffer. Although the string literal itself cannot be changed, its characters can be copied into a buffer and the buffer can be changed. The second function appends additional characters to the string in the buffer by copying characters from a second literal. The third function converts characters in the buffer to lower case. The buffer is not a string literal, so the characters it contains can be altered.
7. Software Attacks!
A common attack on software (especially software written in C) is to send more characters into a buffer than the buffer can hold. Something will go wrong when this happens, and the attacker hopes to take advantage of whatever happens.
For example, a once successful attack on Web servers was to send the server a very long URL, somehing like:
http://pentagon.gov/gobbleygook and more gobbelygook and more and more .... and now for some machine code: XXXXXX
With some fiddling, the bogus URL would overflow the buffer allocated for it and the machine code part of the bogus URL would be placed somewhere in the server's memory and would eventually be executed. If you are writing secure code, you can never assume that a buffer is big enough.
