created: 11/14/2007; revised 03/06/2009
These puzzles involve characters and null-terminated strings. The string puzzles are an opportunity to practice using pointers. You could solve the puzzles using character arrays and indexing, but try to solve them using character pointers.
[E-1]Write a function that determines if a character
is an upper case character 'A' through 'Z'. If so, return 1, otherwise
return zero. Here is a prototype for the function:
int isUppercase( int ch );
The argument for the function is an int, with
the eight bit ASCII character in the low order byte.
(Review the Gotcha from the introduction about why the argument is an int.)
Here is a skeleton of a testing program. Finish it by completing the function. With a programming environment (such as Bloodshed Dev-C++) use copy-and-paste to copy this code into the editor window and then save it to a source file.
/* Puzzle S01 -- detect upper case characters */
#include <stdio.h>
#include <stdlib.h>
int isUppercase( int ch )
{
. . . .
}
int main(int argc, char *argv[])
{
char trials[] = {'a', 'B', 'Z', ' ', '+', 'z', 'Z', 0x33 };
int j, ch;
for ( j=0; j<sizeof(trials); j++ )
{
ch = trials[j];
if ( isUppercase( ch ) )
printf("%c is upper case\n", ch);
else
printf("%c is NOT upper case\n", ch);
}
system("PAUSE");
return 0;
}
Note: this function is similar to the function isupper()
described in <ctype.h>. In professional-level code,
use the standard function rather than your own.
![]()
[E-1]Write a function isWhitespace()
that determines if a character (contained in an int) is a whitespace
character. Whitespace is any of the following characters: space, tab, carriage
return, newline, vertical tab, or form feed. Here is a testing program:
/* Puzzle S02 -- is a character whitespace? */
#include <stdio.h>
#include <stdlib.h>
int isWhitespace( int ch )
{
}
int main(int argc, char *argv[])
{
char trials[] = {'a', 'B', ' ', '+', 'z', 0x33, 0x09, 0x0A, 0x0B, 0x0C, 0x0D };
int j, ch;
for ( j=0; j<sizeof(trials); j++ )
{
ch = (int)trials[j] ; /* char in low order byte */
printf("%02X ", ch );
if ( isWhitespace( ch ) )
printf("is whitespace\n");
else
printf("is NOT whitespace\n");
}
system("PAUSE");
return 0;
}
Consult the table of ASCII in the introduction to determine the bit patterns for the whitespace characters.
Note: this function is similar to the function isspace()
described in <ctype.h>. In professional-level code,
use the standard function rather than your own.
![]()
[E-4]Write a function that converts an upper case
character to a lower case character and leaves all other characters unchanged.
The character to be converted is passed (by value) as an int. The
return value of the function is the converted character. Here is a testing program:
/* Puzzle S03 -- to lower case */
#include <stdio.h>
#include <stdlib.h>
int isUppercase( int ch )
{
}
int toLowerCase( int ch )
{
}
int main(int argc, char *argv[])
{
char trials[] = {'a', 'B', 'C', '+', 'z', 0x33, 0x0C, 0x0D };
int j, ch;
for ( j=0; j<sizeof(trials); j++ )
{
ch = (unsigned int)trials[j] ; /* char in low order byte */
printf("%c ", ch );
printf("to lower case: %c\n", (char)toLowerCase(ch) );
}
system("PAUSE");
return 0;
}
Note: this function is similar to the function toLower()
described in <ctype.h>.
![]()
[E-4]Write function strlen() that
computes the length of a string. The length of a null-terminated string is the
number of characters in it, not counting the null at the end. An empty string
(one that contains only the null byte) has a length of zero. Here is a
prototype for the function:
int strlength( char *p )
The function's parameter is a pointer to the first byte of the string. Write the function to move the pointer through the successive bytes of the string, incrementing a counter as it does so, until the pointer hits the NUL. Here is a testing program:
/* Puzzle S04 -- string length */
#include <stdio.h>
#include <stdlib.h>
int strlength( char *p )
{
}
int main(int argc, char *argv[])
{
char *trials[] = {"String of length 19", "X", "", "Yet another string",
"End of\nlines should\nwork fine."};
int j, ch;
for ( j=0; j<sizeof(trials)/sizeof(char *); j++ )
{
printf("%s\nis length %d\n\n", trials[j], strlength( trials[j] ) );
}
system("PAUSE");
return 0;
}
Note 1: Don't call your function strlen() like the
standard function
or you may have trouble compiling because of a name conflict.
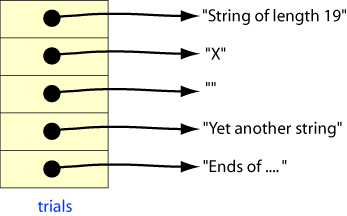
Note 2:
The array trials consists of cells which contain the addresses of
string literals.
The size of each cell is sizeof(char *) so the
number of cells in the array is sizeof(trials)/sizeof(char *)
![]()
[E-4] Write function that converts each upper
case character of a string to lower case. If a character is not upper case,
it is not altered. Here is a testing program:
/* Puzzle S05 -- string to lower case */
#include <stdio.h>
#include <stdlib.h>
int toLowercase( int ch )
{
}
void strToLower( char *p )
{
}
int main(int argc, char *argv[])
{
char trials[6][100] = {"UPPER CASE + lower case", "X", "", "Yet another string",
"End Of\nLines Should\nWork Fine.", "The game is afoot!"};
int j ;
for ( j=0; j<6; j++ )
{
printf("Original : %s\n", trials[j]);
strToLower( trials[j] );
printf("Converted: %s\n\n", trials[j] );
}
system("PAUSE");
return 0;
}
Note: The array trials contains six strings (of up to 99 characters
each). These strings are not constants, so they can be altered by strToLower().
The following testing program would NOT work, because it attempts to alter a
constant string literal:
int main(int argc, char *argv[])
{
char trial = "Immutable string LITERAL!" ;
printf("Original : %s\n", trial );
strToLower( trial ); /* Run-time error */
printf("Converted: %s\n", trial );
}
However, with some C compilers the above defective program actually will compile and run without reported error.
![]()
[M-5]Write function that copies the characters
contained in a source string to a target string. Copy the final null byte from
the source string, as well. Assume that the target string has at least as many
characters as the source string. The target string must already exist before
the function is called, and any characters in it are over-written. Here is a
prototype for the function:
void stringCopy( char *copy, char *source );
Here is a picture of what it does. The two strings are contained in buffers, which may have room for more characters than are logically contained in the null-terminated string. The buffers need not be the same size.
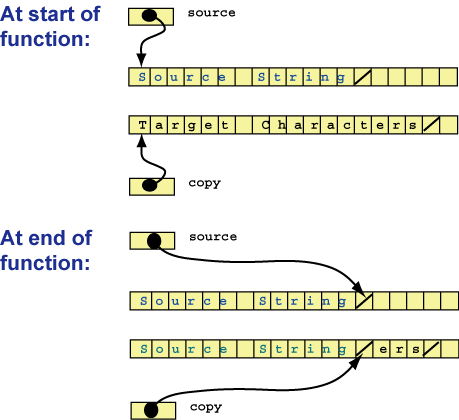
The two pointers move together through their respective strings until the source
pointer hits the null at the end of its string. The function does nothing with
the characters in the copy buffer that are left over from its original contents.
From the picture, it looks like the function looses track of where each
buffer begins, and this is true.
But the caller of the function (main in this case)
still has the original values with which it called the function.
Here is a testing program:
/* Puzzle S06 -- string copy */
#include <stdio.h>
#include <stdlib.h>
void stringCopy( char *copy, char *source )
{
}
int main(int argc, char *argv[])
{
char buffer[100];
char *trials[] =
{
"The game is afoot!",
"Genius is an infinite capacity for taking pains.",
"So is programming.",
"",
"As always,\nlinefeeds should\nwork.",
"Will\ttabs\t\tconfuse\tthings?",
"For great fun, change the buffer size to 5!"
};
int j ;
for ( j=0; j<sizeof(trials)/sizeof(char *); j++ )
{
stringCopy( buffer, trials[j] );
printf("%s\n", buffer);
}
system("PAUSE");
return 0;
}
This function is similar to the standard function strcpy() described
in <strings.h> .
If you change the buffer size to 5, stringCopy() will not know
it, and will blindly copy characters into the first 5 bytes of the buffer and
beyond. This will likely clobber something else in memory. To see the effect
of this, you may have to move the declaration of the buffer around in the code
so that something crucial gets clobbered. Put it just before j,
for example.
To somewhat allievate this problem, the standard function strncpy()
described in <strings.h> requires an additional argument,
the length of the buffer.
![]()
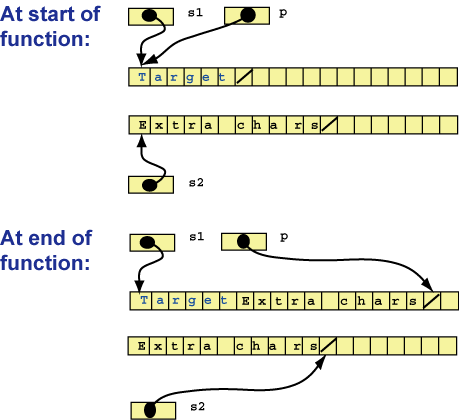
[M-5]Write function
stringConcat(char *s1, char *s2)s2 to
the end of the string s1. The null character that ends s1
is overwritten with the first character in s2 and a new null character
is place at the end of the combined strings. String s1 is assumed
to be contained in a buffer that has enough room for the combined length of
the strings. The string s2 is not affected. The function returns
the address of the first byte of s1 (which is the same value of
s1 that is passed into the function.) This function is similar to the
standard strcat() function. Here is a picture that shows the operation
of the function:
The variable p is local to the function so that the value in s1 can be returned, as per specifications. Here is a testing program:
#include <stdio.h>
#include <stdlib.h>
void stringCopy( char *copy, char *source )
{
}
char *stringConcat( char *s1, char *s2 )
{
}
int main(int argc, char *argv[])
{
char buffer[ 100 ];
char *trialsA[] =
{
"The game is",
"Genius is an infinite capacity",
"So is",
"",
"",
"As always,\n",
"Will\ttabs\t",
"For great fun, "
};
char *trialsB[] =
{
" afoot!",
" for taking pains.",
" programming.",
"",
"concatenated to an empty string",
"linefeeds should\nwork.",
"confuse\tthings?",
" change the buffer size to 5!"
};
int j ;
for ( j=0; j<sizeof(trialsA)/sizeof(char *); j++ )
{
stringCopy( buffer, trialsA[j] );
stringConcat( buffer, trialsB[j] );
printf("%s\n", buffer );
}
system("PAUSE");
return 0;
}
stringCopy() is used in the testing program and also might be used
in stringConcat().
![]()
[H-8]Write a function which removes whitespace
characters from the beginning and end of a string. For example, the string
" Spaces before, spaces after "will be trimmed to
"Spaces before, spaces after"
Whitespace in the middle of a string will not be removed. Use the isWhitespace()isspace()
#include <stdio.h>
#include <stdlib.h>
void trim( char *p )
{
}
int main(int argc, char *argv[])
{
char buffer[ 100 ];
char *trials[] =
{
" The game is afoot! ",
"The game is afoot!",
" The game is afoot!",
"The game is afoot! ",
"\n\nNewLines and tabs count as Whitespace\n\n\t\t",
"\n\tInternal\ttabs\t \tShould Remain \t",
"",
"Empty strings should pass right through",
" \t\n\t ",
"Strings of all whitespace should be reduced to empty"
};
int j ;
for ( j=0; j<sizeof(trials)/sizeof(char *); j++ )
{
strcpy( buffer, trials[j] );
trim( buffer );
printf("-->%s<--\n", buffer );
}
system("PAUSE");
return 0;
}
![]()
[H-12]Write function that accepts a string of
digits and computes the corresponding int. For example the string
"123" will be converted into the int value 123. (Usually
this is called "converting the string into an integer," although the
string itself is not actually changed.) Assume that the string might start with
an optional plus or minus sign and that the the string is terminated by a null.
If one of the characters is not a digit, stop the conversion and return whatever
value has been calculated so far. Here is a prototype:
int stringToInt( char *p );
Use Horner's method to calculate the int:
value = 0 start with leftmost digit while digit is '0' through '9' value = value * 10 value = value + integer equivalent of digit move to next digit return value
You can write the function using entierly your own code, or use the standard
functions isdigit() and toint() from <ctype.h>
. Here is a testing function:
/* Puzzle S09 -- string to int */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
int stringToInt( char *p )
{
}
int main(int argc, char *argv[])
{
char *trials[] =
{
"1",
"12",
"+1",
"-8",
"+2003",
"-345",
"9876 ",
"12o5",
"rats",
"--oh dear--",
"+ 234",
"++45"
};
int j ;
for ( j=0; j<sizeof(trials)/sizeof(char *); j++ )
{
printf("%s is converted into: %d\t\tshould be: %d\n", trials[j],
stringToInt( trials[j]), atoi( trials[j]) );
}
system("PAUSE");
return 0;
}
The testing program compares the output of our stringToInt() with
the standard atoi() which does the same thing. If the string starts
with spaces, or there are spaces between the optional sign and the digits, then
the conversion stops.
![]()
[H-20]Write function that accepts a string of
digits and converts it into a double. For example the string "123.456"
will be converted into the double value 123.456. Assume that the
string might start with an optional plus or minus sign and that the the string
is terminated by a null. There may be zero or one decimal point in the string.
If one of the characters is not a digit (or a correctly possitioned plus, minus,
or decimal point), stop the conversion and return whatever value has been calculated
so far. Here is a prototype:
int stringToDouble( char *p );
Use Horner's method to calculate the integer part of the double. When the decimal point is encountered, start a divisor out at 10 and increase it by a factor of 10 for each new digit. Divide each digit past the decimal point by the current divisor and add the result to the current sum.
Here is a testing function:
/* Puzzle S10 -- string to double */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
double stringToDouble( char *p )
{
}
int main(int argc, char *argv[])
{
char *trials[] =
{
"1",
"1.2",
"+1",
"-8.000",
"+2003.99",
"-3.45",
"98.76 ",
"12..5",
"rats",
"+95.M",
"+ 234",
".999",
"+1.345E+005" /* Our function will not work for this */
};
int j ;
for ( j=0; j<sizeof(trials)/sizeof(char *); j++ )
{
printf("%s is converted into: %lf\t\tshould be: %lf\n", trials[j],
stringToDouble( trials[j]), atof( trials[j]) );
}
system("PAUSE");
return 0;
}
The testing program compares the output of our stringToDouble()
with the standard atof() which does the same thing. If the string
starts with spaces, or there are spaces between the optional sign and the digits,
then the conversion stops.
The standard atof()can convert strings that use scientific notation,
as in the last test case above. Our function will fail with this. It would not
be too hard to extend our function to deal with scientific notation.
![]()
 — Return to the main contents page
— Return to the main contents page